python兼职
调用
内网穿透
sqlserver
http
excel
图像增强处理
办公软件
进程
共阴极-共阳极判定
网页设计
cve-2022-21449
gnu
串口中断
CalBioreagents
信号完整性
多版本并发控制机制
结构体内存对齐方式
滑动窗口
swiftu
分词
2024/4/13 2:39:16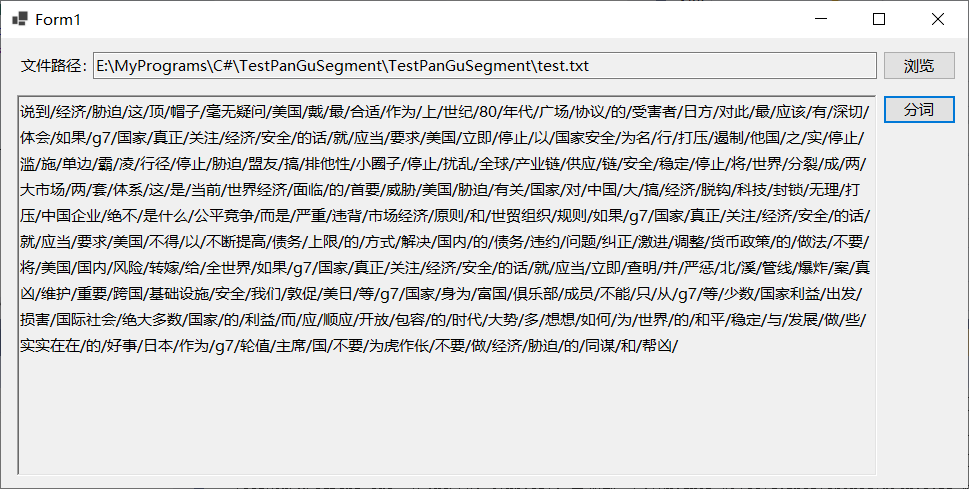
测试分词工具Lucene.Net.Analysis.PanGu(盘古分词)
从微信公众号及百度文章来看,全文检索的前置工作是分词,首先将要做全文检索的内容分词,然后采用全文检索模块或工具进行全文检索。参考文献4介绍了基于Lucene.net实现全文检索的大致思路,其采用的是Lucene.net盘古分词的方式实现。…

常用的自然语言处理分词工具
中科院ICTCLAS分词东北大学NIUPARSER清华大学THULAC复旦大学FUNLP HanLP MMSEG JCSEG Ansj LTPLingPipeWORDMMSEG4JIK-ANALYZERSMARTCNJIEBAStanford parserBerkeley parsernltk

NLP之汉语自动分词
汉语自动分词就是让计算机识别出汉语文本中的‘词’,在词与词之间自动加上空格或其他边界标记。
目录
一.汉语自动分词中的基本问题
1.1分词规范问题
2.2歧义切分问题
3.未登录词问题
二.汉语分词方法
1.N-最短路径方法
2.基于词的n元语法模型的分词方法
3…
NLP之jieba中文分词官方文档
jieba
“结巴”中文分词:做最好的 Python 中文分词组件
特点
支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析;全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快࿰…
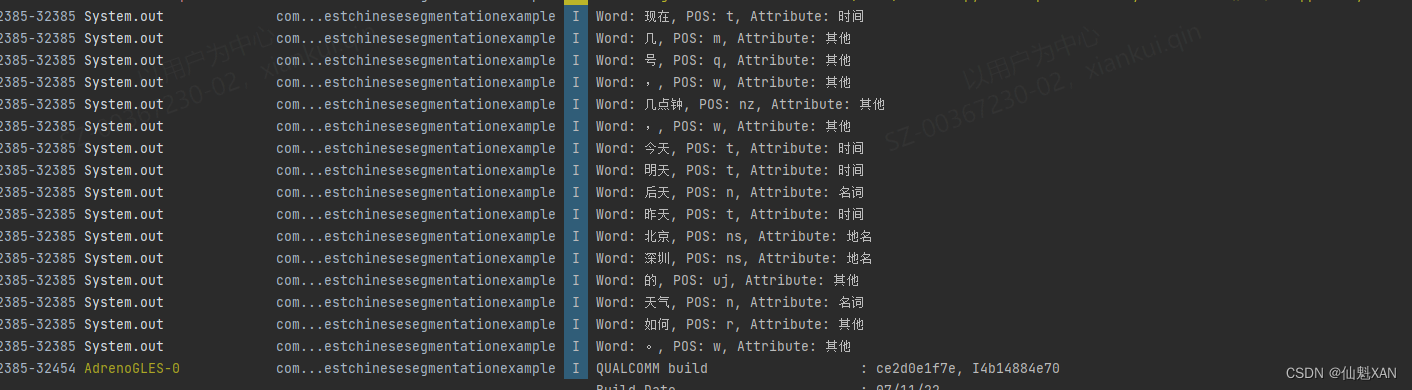
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 目录
Android Studio 之 Android 中使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
一、简单介绍
二、实现原理…
Elasticsearch 文本分析器(下)
字符过滤器 注意:字符过滤器用于在将字符流传递给分词器之前对其进行预处理 html_strip HTML元素替换过滤器
此过滤器会替换掉HTML标签,且会转换HTML实体 如:& 会被替换为 &。
{"tokenizer": "keyword","…
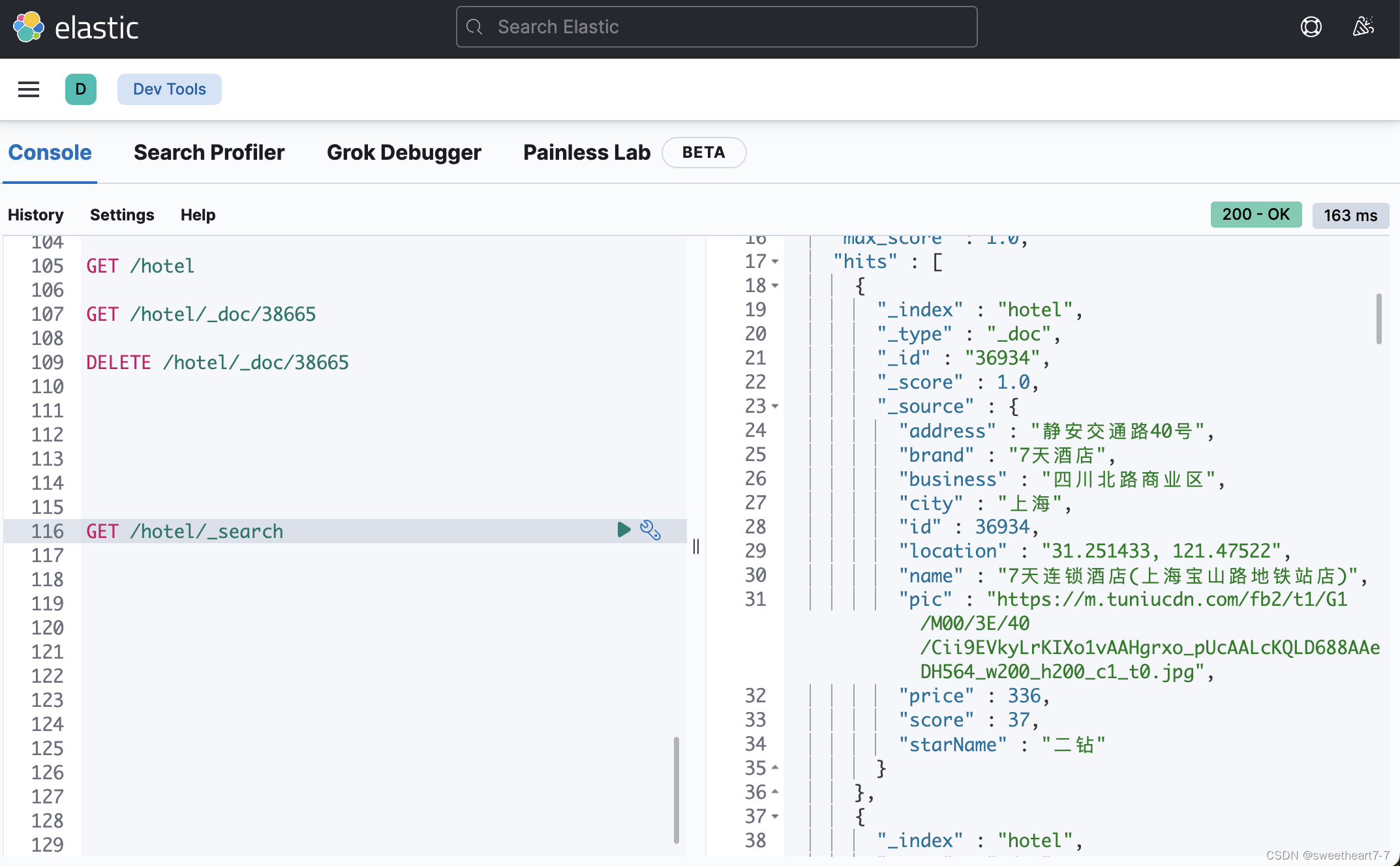
Spring Cloud学习(九)【Elasticsearch 分布式搜索引擎01】
文章目录 初识 elasticsearch了解 ES倒排索引ES 的一些概念安装es、kibana安装elasticsearch部署kibana 分词器安装IK分词器ik分词器-拓展词库 索引库操作mapping 映射属性索引库的 CRUD 文档操作添加文档查看、删除文档修改文档Dynamic Mapping RestClient 操作索引库什么是Re…

自然语言处理从小白到大白系列(6)说说中文分词那些事
文章目录一. 分词常用方法1.1 基于词表的方法最大匹配法全切分路径选择法1.2 基于统计模型的方法1. n元语法模型2. 隐马尔可夫模型(Hidden Markov Model ,HMM)3. 条件随机场模型(Conditional Random Fields,CRF&#x…


hanlp,pkuseg,jieba,cutword分词实践
总结:只有jieba,cutword,baidu lac成功将色盲色弱成功分对,这两个库字典应该是最全的
hanlp[持续更新中]
https://github.com/hankcs/HanLP/blob/doc-zh/plugins/hanlp_demo/hanlp_demo/zh/tok_stl.ipynb
import hanlp
# hanlp.pretrained.tok.ALL # 语种见名称最…
NLP之jieba分词原理简析
一、jieba介绍
jieba库是一个简单实用的中文自然语言处理分词库。
jieba分词属于概率语言模型分词。概率语言模型分词的任务是:在全切分所得的所有结果中求某个切分方案S,使得P(S)最大。
jieba支持三种分词模式:
全模式,把句子…

python︱六款中文分词模块尝试:jieba、THULAC、SnowNLP、pynlpir、CoreNLP、pyLTP
THULAC 四款python中中文分词的尝试。尝试的有:jieba、SnowNLP(MIT)、pynlpir(大数据搜索挖掘实验室(北京市海量语言信息处理与云计算应用工程技术研究中心))、thulac(清华大学自然语…
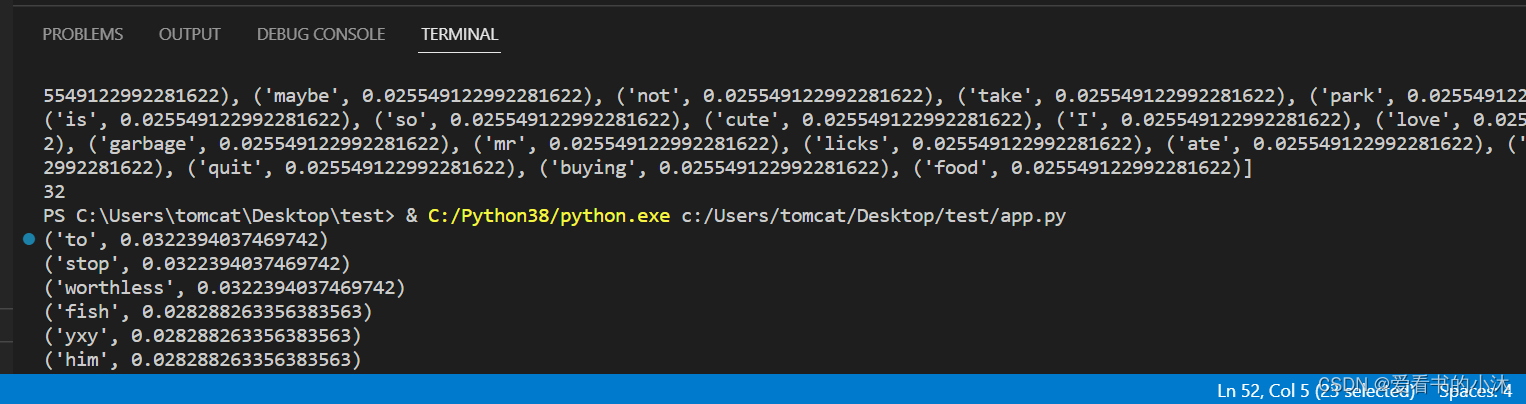
【小沐学NLP】Python实现TF-IDF算法(nltk、sklearn、jieba)
文章目录 1、简介1.1 TF1.2 IDF1.3 TF-IDF2.1 TF-IDF(sklearn)2.2 TF-IDF(nltk)2.3 TF-IDF(Jieba)2.4 TF-IDF(python) 结语 1、简介
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Fr…
分词算法--正向最大匹配和逆向最大匹配实现
本代码来源于《python自然语言处理实战 核心技术与算法》一书中逆向最大匹配算法实现:
假设已经有正向匹配算法源码,则可以将文档进行倒序处理,生成逆序文档,然后根据逆序词典,对逆序文档使用正向最大匹配法处理即可。…

手把手教你Python3使用Jieba工具
疫情宅在家,只能静下心来弄毕设~
话不多说,直接上干货,本篇博客包含:
中文分词添加自定义词典词性标注关键词抽取环境:
Python3.5Jieba-0.39Pycharm2018
一、安装jieba
在安装有python3 和 pip 的机子上࿰…

使用ES对一段中文进行分词
ES连接使用org.elasticsearch.client.RestHighLevelClient。获取分词的代码如下: import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.http.util.EntityUtils;
import org.elas…

Unity Android 之 使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
Unity Android 之 使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理 目录
Unity Android 之 使用 HanLP 进行句子段落的分词处理(包括词的属性处理)的简单整理
一、简单介绍
二、实现原理
三、注意事项
四、效…
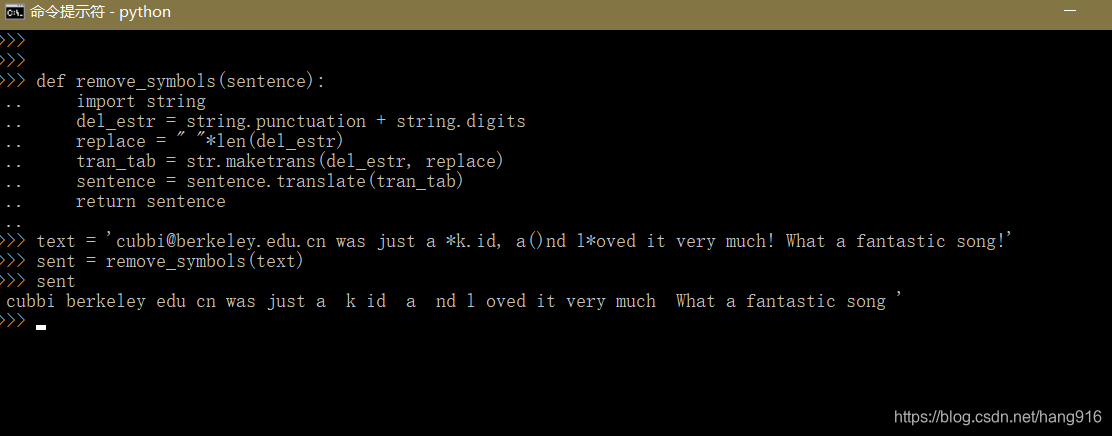
Python将英文标点替换成空格
def remove_symbols(sentence):"""Remove numbers and symbols from ASCII"""import stringdel_estr string.punctuation string.digits # ASCII 标点符号,数字replace " "*len(del_estr)tran_tab str.maketrans(del_…
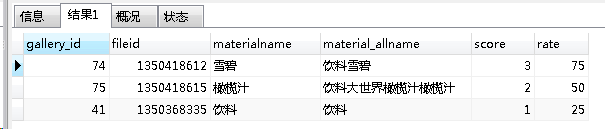
商品酒水图片自动推荐技术实践
前段时间,博主公司的产品经理想出一个点子,简单说让自己搞一个图库,让商家轻松方便的配置商品的图片,最好是一键配置完毕。
这是他们的宣传语
设置一次酒水,要花一周时间
摄影师拍照 设计师修图
运营配图 办公室包…
HarmonyOS学习路之开发篇—AI功能开发(分词)
分词概述
随着信息技术的发展,网络中的信息量成几何级增长逐步成为当今社会的主要特征。准确提取文本关键信息,是搜索引擎等领域的技术基础,而分词作为文本信息提取的第一步则尤为重要。
分词作为自然语言处理领域的基础研究,衍…

【小沐学NLP】Python使用NLTK库的入门教程
文章目录 1、简介2、安装2.1 安装nltk库2.2 安装nltk语料库 3、测试3.1 分句分词3.2 停用词过滤3.3 词干提取3.4 词形/词干还原3.5 同义词与反义词3.6 语义相关性3.7 词性标注3.8 命名实体识别3.9 Text对象3.10 文本分类3.11 其他分类器3.12 数据清洗 结语 1、简介
NLTK - 自然…
Python发布API
分为两个文件,一个方法,一个服务。 先看服务文件: import json import translateUtil from flask import Flask, request from flask_cors import CORS
app Flask(__name__) # 实例化 server,把当前这个 python 文件当做一个服…

Python3中的 jieba分词
jiebaGitHub地址:https://github.com/fxsjy/jieba
参考地址:https://www.cnblogs.com/jiayongji/p/7119065.html
中文分词
对于NLP(自然语言处理)来说,分词是一步重要的工作,市面上也有各种分词库&#…
Lucene入门实例
一、Lucene的下载
下载链接:http://lucene.apache.org/ 下载后,解压缩,如下图所示(我下载的版本是5.3.1):
开发包说明:
core:核心jar包analysis:语言分析器&#x…

测试C#分词工具jieba.NET
jieba.NET是jieba中文分词的C#版本,后者是优秀的Python中文分词组件GitHub中得到超过3万星。jieba.NET支持中文分词、关键词提取、词性标注等功能,本文主要测试其中文分词的功能基本用法。 新建测试项目,在NuGet管理器中添加jieba.NET。 …
Solr分词器配置与功能介绍
二、 SOLR搭建企业搜索平台--中文分词这篇文章,主要说的是 怎么在solr中加入中文分词1、下载分词器:http://code.google.com/p/mmseg4j/2、将解压后的mmseg4j-1.8.2目录下的mmseg4j-all-1.8.2.jar拷贝到Tomcat _HOME\webapps\solr\WEB-INF\lib目录下。3、…
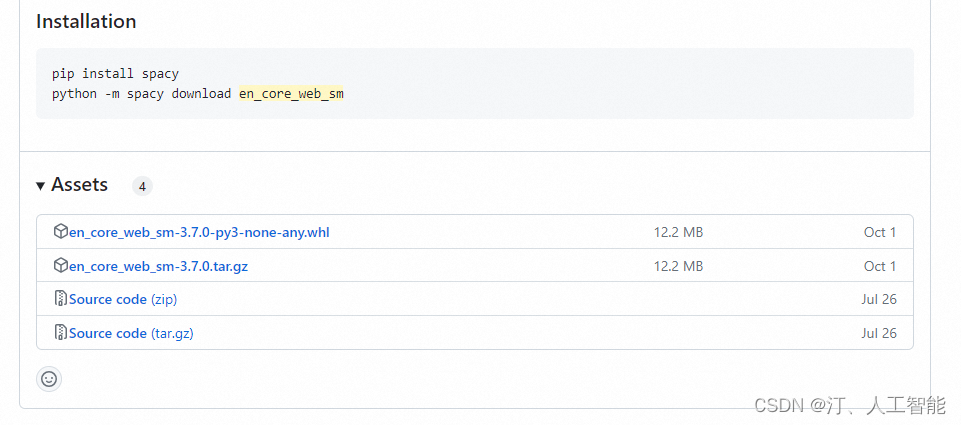
自然语言处理(NLP)-spacy简介以及安装指南(语言库zh_core_web_sm)
spacy 简介
spacy 是 Python 自然语言处理软件包,可以对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化等。
1.安装 spacy
使用 “pip install spacy" 报错, 或者安装完 spacy,无法正…
